
Dziś rzucimy trochę światła na podstawę semantycznej sieci czyli tajemniczy Resource Description Framework. Zobaczymy jak opisać znaczenie naszych danych i dlaczego sieć jest grafem. Zahaczymy też o RDFS i OWL.
Resource Description Framework można przetłumaczyć jako format opisu zasobów. Jest to język, którym opisujemy dane oraz powiązania między nimi. Uzupełnieniem jest RDFS (RDF Schema), który opisuje znaczenie naszych danych.
Grafy są wszędzie
Nauczmy się najpierw myśleć grafami.
Wszystko, co opisujemy można ująć w graf. Normalnie patrzymy na grafy jako na zbiór wierzchołków i krawędzi. W RDF jest inaczej. Podstawowym elementem jest trójka (triplet) czyli dwa wierzchołki oraz łącząca je krawędź.
Większość znanych nam danych możemy pokazać na grafie. Weźmy najprostszy przykład:
<img src="http://google.com/images/logo.png" alt="Google Logo" width="275" align="right" />
Zwykły obrazek wstawiony w HTML. Gdzie tu graf? Gdzie tu trójka? Popatrzmy na to w ten sposób:
| podmiot | relacja | wartość |
|---|---|---|
| img | src | http://google.com/images/logo.png |
| img | alt | Google Logo |
| img | width | 275 |
| img | align | right |
Mamy więc zestaw trójek. Oczywiście nie musimy ograniczać się do jednego podmiotu. Nasza wartość może stać się kolejnym:
| podmiot | relacja | wartość |
|---|---|---|
| http://google.com/images/logo.png/ | author |
Możemy te same dane przedstawić jako graf:
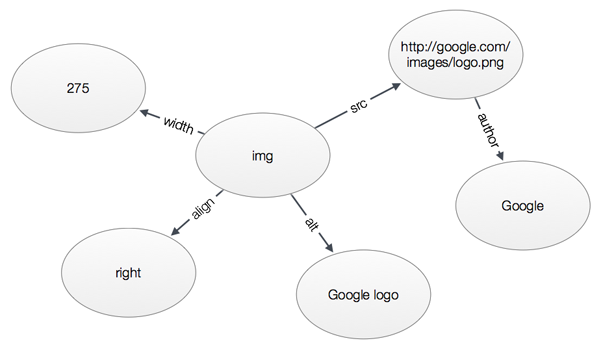
Naszą relację w języku RDF nazywamy orzeczeniem lub predykatem.
Semantyczne trójki
W semantycznej sieci wszystko sprowadza się do trójek. Opisujemy podmiot nadając mu wartość, która jest oznaczona jakimś predykatem (czyli relacją). To właśnie relacja ma znaczenie semantyczne. Możemy napisać zdania typu:
- A zna K
- A jest Człowiek
- A ma_imię Adam
- K jest Kot
- K lubi C
- C jest Cheesburger
Takie trójki mówią nam, że Adam zna Kota, który lubi cheesburgery. Najważniejsze tu są słowa „zna”, „jest”, „ma_imię”, „lubi”. To ich znaczenie musimy zdefiniować. Jak to zrobić? Oczywiście za pomocą trójek:
- „zna” znaczy „Podmiot zna obiekt określony wartością”
- „jest” znaczy „Podmiot jest tworem określonym przez wartość”
- „ma_imię” znaczy „Podmiot posiada pierwsze imię określone w wartości”
- „lubi” znaczy „Podmiot lubi obiekt określony w wartości”
Ale kto to ma czytać i jak parsować? Oczywiście nie komputer. Te definicje są przeznaczone dla człowieka, programisty, który pisze aplikację czytającą nasze dane.
Mamy tu jedną nieścisłość. Gdzie jest definicja predykatu (relacji) „znaczy”? Oczywiście trzeba ją dodać:
- „znaczy” znaczy „Podmiot znaczy to, co opisano ludzkim językiem w wartości”
Predykat zdefiniował sam siebie. Gdybyśmy byli komputerem, wpadamy w rekurencyjną pętlę. Na szczęście większość programistów rozumie język ludzki i potrafi domyślić się, że ma kupić parówki.
RDF i RDFS
Bardziej formalnie nasze trójki są zdefiniowane w RDF i RDFS. Ponieważ jeden korzysta z drugiego i na odwrót, rozpatrzmy je razem. Mamy definicję:
| rdfs:comment | rdfs:comment | A description of the subject resource. |
Nasz obiekt comment zdefiniował sam siebie jako opis. W domyśle – dla człowieka.
Dalej wszystko jest opisywane komentarzem. Np.
| rdfs:label | rdfs:comment | A human-readable name for the subject. |
| rdfs:seeAlso | rdfs:comment | Further information about the subject resource. |
I tak dalej… kolejne definicje są dodawane bazując na poprzednich.
Na podstawie RDF i RDFS powstały kolejne zbiory definicji (ontologie) nadające znaczenie predykatom (relacjom). Warto wspomnieć o OWL (Web Ontology Language) oraz Dublin Core. Możemy dodawać własne ontologie ale o tym zaraz.
Jak z tego skorzystać?
Dublin Core definiuje znaczenie wielu podstawowych predytaktów takich jak „date”, „title”, „subject”, „language” itp. Skorzystamy z niego w tym przykładzie.
Wyobraźmy sobie API RESTowe, które zwraca dane w formie xm
<rdf:Description rdf:about="http://adam.wroclaw.pl">
L. Zamiast jednak podawać prosty XML podamy go od razu w formacie RDF:
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description rdf:about="http://adam.wroclaw.pl">
<dc:description>W3Schools - Free tutorials</dc:description>
<dc:creator>Adam</dc:creator>
<dc:type>Blog</dc:type>
<dc:format>text/html</dc:format>
<dc:language>pl</dc:language>
</rdf:Description>
</rdf:RDF>
Co tu się stało? Popatrzmy się linia po linii. Najpierw definiujemy dwie przestrzenie nazw XML:
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:dc="http://purl.org/dc/elements/1.1/"
Odtąd wszystkie elementy z przedrostkiem „rdf” należą do przestrzeni zdefiniowanej przez pierwszy URL. Wszystko z przedrostkiem „dc” należy do drugiej przestrzeni. Więcej o przestrzeniach nazw w XML można poczytać tutaj.
Dalej zaczynamy opisywać dane:
<rdf:Description rdf:about="http://adam.wroclaw.pl">
Rozpoczęliśmy element, który opisuje dane dotyczące jakiegoś zasobu. Element rdf:Description mówi, że coś opisujemy a rdf:about wskazuje co. Następnie korzystamy z nazw zdefiniowanych w Dublin Core:
<dc:description>Wyzwania Współczesnego Webdevelopera</dc:description> <dc:creator>Adam</dc:creator> <dc:type>Blog</dc:type> <dc:format>text/html</dc:format> <dc:language>pl</dc:language>
Każdy element opisuje jakieś dane. Opis, autor, typ danych, format itp.
Co nam to daje? Moglibyśmy przecież zwrócić zwykły XML bez przedrostków. Np. taki:
<?xml version="1.0"?> <Description about="http://adam.wroclaw.pl"> <description>W3Schools - Free tutorials</description> <creator>Adam</creator> <type>Blog</type> <format>text/html</format> <language>pl</language> </Description>
Dane są te same. Ale w takiej sytuacji nikt nie wie co poszczególne tagi znaczą. Czy type oznacza typ danych tekstowy, typ mime, czy do czegoś się odnosi? Możemy się domyślać co to wszystko znaczy.
RDF daje nam pewność. Możemy zajrzeć do specyfikacji np. dc:type dowiadujemy się, że opisuję naturę, rodzaj zasobu. Podobnie tag dc:creator jest zdefiniowany jako nazwa osoby, organizacji lub serwisu odpowiedzialnego za stworzenie zasobu.
Jeśli teraz raz napiszemy parser rozumiejący definicje RDF i Dublin Core, będziemy mogli wykorzystać go we wszystkich zasobach korzystających z tego standardu.
Klasy, podklasy i OWL
OWL czyli Web Ontology Language definiuje klasy, które grupują definicje. O klasach myślimy tu jako o grupach, zbiorach danych tak jak w teorii mnogości.
Klasy służą do oddzielenia abstrakcyjnej definicji zbioru danych od poszczególnych elementów (individuals). Możemy mieć zbiór danych np. Samochodów, w tym zbiorze mieć zbiór Opli a w nim poszczególne modele. Definicja wyglądałaby tak:
<?xml version="1.0"?>
<!DOCTYPE RDF [
<!ENTITY vso "http://purl.org/vso/ns#" >
<!ENTITY dbpedia "http://dbpedia.org/resource/" >
<!ENTITY coo "http://www.volkswagen.co.uk/vocabularies/coo/ns#" >
]>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:owl="http://www.w3.org/2002/07/owl#"
xmlns:gr="http://purl.org/goodrelations/v1#"
xmlns:coo="&coo;"
xmlns:vso="&vso;"
>
<owl:Class rdf:ID="opel">
<rdfs:subClassOf rdf:resource="&vso;Automobile"/>
<gr:hasManufacturer rdf:resource="&dbpedia;Opel"/>
<rdfs:label>Opel cars</rdfs:label>
</owl:Class>
<opel rdf:ID="opel-corsa">
<vso:driveWheelConfiguration rdf:resource="&vso;FWD"/>
<rdf:type rdf:resource="&coo;BaseModel"/>
<rdfs:label>Corsa</rdfs:label>
</opel>
<opel rdf:ID="opel-frontera">
<vso:driveWheelConfiguration rdf:resource="&vso;4WD"/>
<rdf:type rdf:resource="&coo;BaseModel"/>
<rdfs:label>Frontera</rdfs:label>
</opel>
</rdf:RDF>
Na pierwszy rzut oka przerażający XML. Rozbijemy go na części pierwsze.
<!DOCTYPE RDF [ <!ENTITY vso "http://purl.org/vso/ns#" > <!ENTITY dbpedia "http://dbpedia.org/resource/" > ]>
Definiujemy sobie dwie encje: &vso; i &dbpedia; Będziemy ich używać w rdf:resource gdzie powinniśmy podać linki. Encje zawierają początki URLi do opisów ontologii (zestawu definicji).
Na potrzeby przykładu znalazłem dwa zbiory definicji (ontologie) opisujące samochody. Vehicle Sales Ontology opisuje pojazdy przeznaczone dla sprzedawców samochodów, łodzi, rowerów itp. Car Options Ontology opisuje samochody i ich opcje, warianty itp.
Dbpedia to wikipedia zapisana w sposób semantyczny. Zawiera definicje artykułów podobnych do wikipedii ale w sposób zrozumiały dla automatów.
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#" xmlns:owl="http://www.w3.org/2002/07/owl#" xmlns:gr="http://purl.org/goodrelations/v1#" xmlns:coo=" http://purl.org/coo/ns#" xmlns:vso="&vso;" >
Mamy zdefiniowane kilka przestrzeni nazw. Znamy już rdf, rdfs. OWL dodaje definicje klas, podklas itp. Gr (Good Relations) definiuje powiązania między obiektami.
<owl:Class rdf:ID="opel"> ... </owl:Class>
Zdefiniowaliśmy zbiór (klasę wg nazewnictwa OWL). Nasza klasa ma identyfikator „opel”.
<rdfs:subClassOf rdf:resource="&vso;Automobile"/>
Klasa „opel” jest podklasą (czyli podzbiorem) klasy Automobile zdefiniowanej w VSO. Gdybyśmy nie stosowali encji, w tym miejscu pojawiłby się adres „http://purl.org/vso/ns#Automobile”.
<gr:hasManufacturer rdf:resource="&dbpedia;Opel"/>
Klasa jest w relacji (ma predykat) „hasManufacturer” (wg Good Relations) czyli ma producenta. Producentem jest firma Opel zdefiniowana w dbpedii pod adresem http://dbpedia.org/resource/Opel.
<rdfs:label>Opel cars</rdfs:label>
Na koniec nadajemy naszej klasie etykietę i opis gdyby jakiś człowiek chciał coś o niej poczytać.
Mamy więc zbiór (klasę), który zdefiniowaliśmy tak:
- Jest podzbiorem Automobili
- Nazywa się „opel”
- Producentem jego elementów jest firma Opel
- Opisaliśmy go etykietą
Następnie leci definicja modelu auta:
<opel rdf:ID="opel-corsa">
...
</opel>
Wcześniej zdefiniowaliśmy klasę „opel”. Teraz możemy użyć jej jako tagu. Oznacza to, że tworzymy element (individual) naszego zbioru (klasy). Element otrzymał nowy identyfikator.
A gdyby nasza klasa „opel” była zdefiniowana gdzieś na sieci w innym pliku? Zrobilibyśmy to samo np. definiując namespace o:http://gdzies.na.sieci/opel.xml. Wtedy w tym miejscu napiszemy <o:opel ...> co daje nam to samo.
<vso:driveWheelConfiguration rdf:resource="&vso;FWD"/>
Tutaj skorzystaliśmy z ontologii VSO aby powiązać rodzaj napędu (vso:driveWheelConfiguration) z konkretną wartością. W tym przypadku http://purl.org/vso/ns#FWD czyli napęd na przód.
<rdf:type rdf:resource="&coo;BaseModel"/>
Nasz obiekt jest elementem (individual) jeszcze jednego zbioru (klasy). BaseModel czyli określenie modeli samochodów. To oznacza, że elementy mogą należeć do wielu klas. Równie dobrze zamiast pisać <opel ...> moglibyśmy napisać <coo:BaseModel ...> a w definicji rdfs:type podalibyśmy naszą klasę „#opel”. Znaczenie się nie zmieni. Nadal nasz element należy jednocześnie do obu klas (zbiorów).
<rdfs:label>Corsa</rdfs:label>
Tu jest już prosto. Nadaliśmy etykietę elementowi.
Druga definicja samochodu (opel-frontera) działa tak samo. Zmieniliśmy tylko ID, rodzaj napędu (na 4 koła) oraz etykietę.
Mamy więc klasę opisującą ople oraz dwa obiekty (individuals, nie wiem jak to dobrze przetłumaczyć) mówiące nam o modelach aut. Teraz gdzieś, w innym pliku możemy skorzystać. Jeśli posiadamy np. Opla Corsę z roku 2006 możemy stworzyć kolejny RDF. W przestrzeniach nazw zaimportujemy naszą ontologię:
opels:http://http://adam.wroclaw.pl/files/opels.rdf
Następnie opiszemy posiadany samochód:
<opel-corsa> <vso:productionDate>2006-01-01</vso:productionDate> </opel-corsa>
Warto zajrzeć do definicji vso:productionDate aby sprawdzić jaką wartość może przyjmować.
Podsumowanie
Kod z przykładu możemy wkleić do walidatora RDF, który rozbije go nam na tabelkę trójek. Dostaniemy tabelę obiekt-predykat-wartość. W ten sposób sprawdzamy nasz RDF i rozumiemy jego znaczenie.
Bardzo dobry opis OWL (a tym samym i RDF i RDFs) jest na stronie w3c. Możemy też przeczytać wprowadzenie do semantycznej sieci w 5 odcinkach.
Dzięki semantycznej sieci znamy nie tylko format danych ale ich znaczenie. Nie musimy już się martwić o dokumentację. Ile razy zastanawialiśmy się czy pole jest takiego czy innego formatu i jak rozumieć dane? Jeśli api mówi do nas w RDF to te problemy będą już za nami.
Ale co gdy nie lubimy XML? Prawie wszyscy rozmawiają dziś w JSONie. O tym będzie w następnym artykule.
Na tego bloga trafiłem niedawno i przeczytałem większość artykułów.
Sporo się nowego dowiedziałem – dzięki.
W przyszłości, w oparciu o zasób semantycznych danych w internecie, prawdopodobnie powstanie sztuczna inteligencja (samo ucząca się). Jednak na razie droga daleka. O semantyce czytam już chyba z dziesiąty rok a w sieci semantycznych danych jak na lekarstwo.
Kiedyś istniał (obecnie brak nowych wpisów) chyba już kultowy blog http://dezinformacja.org/tarpit/temat/semweb Sporo informacji tam było.
To prawda, o semantyczności pisano od dawna. Z praktycznym wykorzystaniem jesteśmy dopiero w przedszkolu.
Sztuczna inteligencja to bardzo odważne słowo. Obecnie semantyczny internet jest przeznaczony raczej dla programistów, którzy potrafią z takich dokumentów sklecić ciekawe dane. Nie widzę na horyzoncie zaczątków samodzielnej sztucznej inteligencji.
Dzięki za linka. Poczytam.